В статье рассмотрим модель данных, организующую информацию в двумерных таблицах, что является основой для хранения и обработки данных в системах управления базами данных (СУБД). Понимание структуры данных и их представления в таблицах помогает разработчикам и аналитикам эффективно управлять информацией, обеспечивая легкий доступ и анализ. Статья будет полезна тем, кто хочет углубить свои знания в работе с данными и понять, как различные модели данных влияют на организацию и использование информации в приложениях.
Презентация по базам данных на тему: Понятие модели данных. Типы моделей данных
Структурная интерпретация совпадает с математическим определением модели как множества с установленными отношениями.
Это отношение определяет аудитории, где проводятся занятия по различным дисциплинам для разных групп.
Базовое отношение — именованное, не производное. Его существование не зависит от других отношений.
Производное отношение определяется через другие именованные отношения и зависит от базовых.
Представление — именованное производное отношение, хранящееся в базе данных в виде определения. Оно не сохраняется в физической памяти системы управления базами данных (СУБД) и формируется на основе других именованных отношений.
Результат запроса — неименованное производное отношение. СУБД не гарантирует его постоянное существование. Чтобы сохранить результат, его можно присвоить именованному отношению.
Промежуточный результат — неименованное производное отношение, полученное в результате подзапроса, вложенного в более сложное выражение.
- Инкапсуляция ограничивает область видимости имени свойства рамками объекта, в котором оно определено. Значение свойства зависит от объекта, в который оно инкапсулировано.
- Наследование расширяет область видимости свойства на всех потомков объекта. Если нужно распространить действие механизма наследования на объекты, не являющиеся непосредственными потомками, в их общем предке определяется абстрактное свойство типа aBs.
- Полиморфизм в объектно-ориентированных языках программирования позволяет одному и тому же коду работать с данными разных типов. Это означает, что в объектах различных типов могут существовать методы с одинаковыми именами.
Эксперты в области информационных технологий подчеркивают важность использования двумерных таблиц для организации данных. Эта модель данных позволяет эффективно структурировать информацию, обеспечивая легкий доступ и анализ. Благодаря своей простоте и наглядности, двумерные таблицы становятся универсальным инструментом для представления различных типов данных, от финансовых отчетов до научных исследований.
Специалисты отмечают, что такая организация способствует быстрому выявлению закономерностей и аномалий, что особенно ценно в условиях больших объемов информации. Кроме того, двумерные таблицы легко интегрируются с современными аналитическими инструментами, что позволяет автоматизировать процессы обработки данных. В результате, компании, использующие эту модель, могут значительно повысить свою конкурентоспособность и оперативность в принятии решений.

Модель данных
В 90-е годы существовали экспериментальные прототипы объектно-ориентиро ванных систем управления базами данных.
| Тип модели данных | Описание | Преимущества | Недостатки |
|---|---|---|---|
| Реляционная модель данных | Данные организованы в виде таблиц со строками (записи) и столбцами (атрибуты), связанные между собой через ключи. | Структурированность, целостность данных, поддержка SQL, масштабируемость. | Сложность проектирования для сложных данных, неэффективность для некоторых типов запросов. |
| Табличная модель данных (в электронных таблицах) | Данные представлены в виде двумерных таблиц, подобно реляционной модели, но без строгой структуры и ограничений. | Простота использования, визуализация данных, быстрый доступ к данным для небольших объемов. | Отсутствие целостности данных, ограниченная функциональность, проблемы с масштабированием. |
| Плоская файловая модель данных | Данные хранятся в виде текстовых или бинарных файлов, часто в формате CSV или TSV. | Простота реализации, легкость обмена данными. | Отсутствие структуры, сложность обработки больших объемов данных, трудно обеспечить целостность данных. |
Интересные факты
Вот несколько интересных фактов о моделях данных, использующих организацию данных в виде двумерных таблиц:
-
Реляционная модель: Двумерные таблицы являются основой реляционной модели данных, предложенной Эдгаром Коддом в 1970 году. Эта модель позволяет организовывать данные в виде таблиц (или отношений), где строки представляют записи, а столбцы — атрибуты. Это упрощает управление данными и их взаимосвязями.
-
SQL и манипуляция данными: Структура двумерных таблиц позволяет использовать язык SQL (Structured Query Language) для выполнения сложных запросов, фильтрации и агрегации данных. SQL стал стандартом для работы с реляционными базами данных и позволяет пользователям легко извлекать и обрабатывать информацию.
-
Нормализация данных: Организация данных в виде двумерных таблиц способствует нормализации, процессу, который уменьшает избыточность и зависимость данных. Нормализация помогает избежать дублирования информации и улучшает целостность данных, что особенно важно в больших и сложных базах данных.

Сетевая модель
Элемент данных — минимальная неделимая единица информации, доступная пользователю, с собственным типом. Агрегат данных — группа элементов данных, объединенных в записи (например, день, месяц, год).
Набор — иерархическая структура из двух уровней, показывающая взаимосвязи между двумя типами записей (один к одному, один ко многим).
Преимущества

Недостатки
Логические модели данных | ЛЕКЦИИ |
Иерархическая и сетевая модели данных были созданы почти на десять лет раньше реляционной модели данных, потому их связь с концепциями традиционной обработки файлов более очевидна.
Недостатки: большая жесткость схемы. Если запрос не соответствует имеющейся иерархии, то его программирование и исполнение требуют значительных усилий. Другой недостаток- сложность внесения изменений.
Достоинства: высокая скорость поиска и возможность адекватно представлять многие задачи в самых различных предметных областях. Высокая скорость поиска основывается на классическом способе физической реализации сетевой модели — на основе списков.
Недостатки: жесткость, т.е. поиск данных и доступ к ним возможен только по тем связям, которые реально существуют в данной конкретной модели.
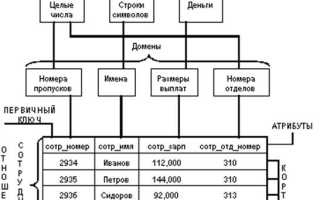
Для реляционной модели (рис. 3) выбрано представление данных на основе математического понятия отношения . Оно очень близко к понятию таблица . По-английски отношение — relation , отсюда и название “ реляционные СУБД”.
Для работы с реляционными СУБД используется стандартизированный язык структурированных запросов SQL ( Structured Query Language ).
Нефункциональность языка запросов SQL . Это означает, что пользователь формулируете не то, КАК надо найти данные, а то, ЧТО необходимо найти.
В объектно-ориентированном программировании отсутствуют общие средства манипулирования данными. Работа с данными ведется с помощью одного из объектно-ориентированных языков программирования общего назначения, обычно это SmallTalk, C++ или Java.
возможность объявить некоторые поля данных и методы объекта как «скрытые», не видимые для других объектов, такие поля и методы используются только методами самого объекта;
Реляционная модель данных
Реляционная модель данных является одной из самых распространенных и эффективных моделей для организации и управления данными. Она была предложена Эдгаром Коддом в 1970 году и с тех пор стала основой для большинства современных систем управления базами данных (СУБД). Основная идея реляционной модели заключается в представлении данных в виде двумерных таблиц, которые называются отношениями.
Каждая таблица состоит из строк и столбцов, где строки представляют собой записи (или кортежи), а столбцы — атрибуты (или поля) этих записей. Например, в таблице “Сотрудники” строки могут содержать информацию о каждом сотруднике, такие как имя, фамилия, должность и зарплата, а столбцы будут представлять эти атрибуты. Это позволяет легко организовывать, извлекать и манипулировать данными.
Одним из ключевых аспектов реляционной модели является использование первичных и внешних ключей. Первичный ключ — это уникальный идентификатор для каждой записи в таблице, который гарантирует, что не будет дубликатов. Внешний ключ, в свою очередь, используется для создания связей между таблицами. Например, если у нас есть таблица “Отделы”, которая содержит информацию о различных отделах компании, мы можем использовать внешний ключ в таблице “Сотрудники”, чтобы связать каждого сотрудника с его соответствующим отделом. Это создает структуру, которая позволяет легко выполнять запросы и получать связанные данные из нескольких таблиц.
Реляционная модель данных также поддерживает использование SQL (Structured Query Language) — языка структурированных запросов, который позволяет пользователям выполнять операции по созданию, чтению, обновлению и удалению данных. SQL предоставляет мощные инструменты для работы с данными, включая возможность выполнения сложных запросов, объединения таблиц и фильтрации данных по различным критериям.
Кроме того, реляционная модель обеспечивает целостность данных через механизмы ограничения, такие как уникальность, обязательность и ссылки. Эти ограничения помогают поддерживать качество данных и предотвращают возникновение ошибок, таких как дублирование или несоответствие данных.
Несмотря на свои многочисленные преимущества, реляционная модель данных имеет и некоторые ограничения. Например, она может быть менее эффективной при работе с большими объемами неструктурированных данных, такими как текстовые файлы или мультимедиа. В таких случаях могут использоваться альтернативные модели данных, такие как документо-ориентированные или графовые базы данных.
Тем не менее, реляционная модель остается основой для большинства бизнес-приложений и систем, требующих надежного и структурированного подхода к управлению данными. Ее простота, гибкость и мощные инструменты делают ее идеальным выбором для многих организаций, стремящихся эффективно управлять своими данными.
Вопрос-ответ
Какая модель данных использует организацию данных в виде двумерных таблиц?
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц.
Какая модель данных хранит данные в виде связанных двумерных таблиц?
Правильный ответ — реляционная база данных, которая организует данные в двумерных таблицах, состоящих из строк и столбцов. Такая структура обеспечивает лёгкий доступ к данным и управление ими. Используя первичные и внешние ключи, реляционные базы данных могут эффективно связывать несколько таблиц.
Какая модель базы данных размещает данные в двумерных таблицах?
Реляционные базы данных. Реляционные базы данных организуют данные в двух измерениях: со строками и столбцами, и используют язык структурированных запросов (SQL) в качестве основного языка.
В какой модели данные представляются в виде связанных таблиц?
Реляционная база данных – это набор данных с заданными взаимосвязями. Реляционная модель объединяет данные в таблицы, где каждая строка представляет собой отдельную запись, а каждый столбец состоит из атрибутов, содержащих значения.
Советы
СОВЕТ №1
Изучите основы работы с двумерными таблицами, такими как Excel или Google Sheets. Понимание функций и формул поможет вам эффективно организовывать и анализировать данные.
СОВЕТ №2
Используйте четкую структуру для своих таблиц: создавайте заголовки столбцов и строк, чтобы данные были легко воспринимаемыми. Это упростит поиск информации и повысит читаемость.
СОВЕТ №3
Регулярно обновляйте и проверяйте данные в таблицах. Это поможет избежать ошибок и обеспечит актуальность информации, что особенно важно при принятии решений на основе данных.
СОВЕТ №4
Не забывайте о визуализации данных. Используйте графики и диаграммы для представления информации, что поможет лучше понять тенденции и взаимосвязи в ваших данных.