Хеш-таблицы с открытой адресацией — это эффективный инструмент для ассоциативных массивов, обеспечивающий быстрый доступ к данным и оптимальное использование памяти. В статье рассмотрим ключевые аспекты выбора хеш-функции, которая критически влияет на производительность хеш-таблицы. Понимание принципов работы хеш-функций и их влияния на распределение данных поможет разработчикам создавать более эффективные алгоритмы, что особенно важно при больших объемах информации и высоких требованиях к скорости обработки.
Хеш-таблицаСодержание а также Хеширование править
В стандартной библиотеке Rust структуры HashMap и HashSet используют метод линейного зондирования с техникой кражи ведра Робин Гуда.
Хеш-таблицы часто более эффективны, чем деревья поиска и другие структуры для поиска в таблицах. Они широко применяются в программном обеспечении, особенно для ассоциативных массивов, индексации баз данных, кеширования и работы с наборами данных.
- Главное преимущество хеш-таблиц — высокая скорость работы, особенно при большом количестве записей. Эффективность возрастает, когда заранее известно максимальное количество записей, что позволяет выделить массив сегментов оптимального размера и избежать изменения его размера в будущем.
- Если набор пар ключ-значение фиксирован и известен заранее (без вставок и удалений), можно снизить среднюю стоимость поиска, тщательно подбирая хэш-функцию, размер таблицы и внутренние структуры данных. Можно создать хеш-функцию, исключающую конфликты или даже идеальную, что позволяет не хранить ключи в таблице.
Эксперты в области программирования подчеркивают важность выбора правильной хеш-функции для хеш-таблиц с открытой адресацией. Эффективная хеш-функция должна обеспечивать равномерное распределение ключей по всей таблице, что минимизирует количество коллизий и, как следствие, время поиска. Специалисты рекомендуют использовать функции, которые учитывают длину ключа и его структуру, чтобы избежать скопления данных в определенных областях таблицы. Кроме того, важно, чтобы хеш-функция была быстрой в вычислении, так как это напрямую влияет на производительность всей структуры данных. В конечном итоге, правильный выбор хеш-функции может значительно повысить эффективность работы хеш-таблицы и улучшить общую производительность приложений.

Хеш-таблица — Hash table.
Если все ключи известны заранее, можно использовать идеальную хеш-функцию для создания идеальной хеш-таблицы, не имеющей коллизий.
| Хеш-функция | Преимущества | Недостатки |
|---|---|---|
h(k) = k % m (Остаток от деления) |
Простая реализация, быстрая работа. | Плохое распределение ключей, если m не является простым числом. Чувствительна к выбору m. Часто приводит к кластеризации. |
h(k) = (a*k + b) % m (Универсальное хеширование с линейной функцией) |
Более равномерное распределение, чем простое деление, если a и b выбраны случайным образом. |
Требует выбора подходящих a, b и m. Не гарантирует идеального распределения. |
h(k) = ((a*k) >> b) % m (Битовое смещение и остаток от деления) |
Быстрая работа, хорошее распределение при правильном выборе a и b. |
Чувствительна к выбору a, b и m. Может быть менее эффективна, чем универсальное хеширование с умножением. |
Хеш-функции из стандартной библиотеки C (например, std::hash) |
Оптимизированы для производительности, часто используют более сложные алгоритмы. | Может быть менее предсказуемым поведением, зависит от реализации. |
h(k) = (k + (k >> 5) + (k >> 11)) % m (Смешивание битов) |
Простое, но эффективное смешивание битов для лучшего распределения. | Может быть менее эффективным, чем более сложные функции, зависит от распределения ключей. |
Интересные факты
Вот несколько интересных фактов о хеш-таблицах с открытой адресацией и выборе хеш-функции:
-
Эффективность хеш-функции: Хорошо спроектированная хеш-функция должна равномерно распределять ключи по всей области хеш-таблицы. Это помогает минимизировать количество коллизий, которые могут возникнуть, когда два разных ключа хешируются в одно и то же значение. Например, простая хеш-функция, которая использует только последние цифры числа, может привести к большому количеству коллизий, если ключи имеют схожие значения.
-
Методы разрешения коллизий: В открытой адресации коллизии разрешаются путем поиска следующей свободной ячейки в массиве. Существует несколько методов, таких как линейное пробирование, квадратичное пробирование и двойное хеширование. Каждый из этих методов имеет свои преимущества и недостатки, и выбор метода может значительно повлиять на производительность хеш-таблицы.
-
Загрузка хеш-таблицы: Оптимальная степень загрузки хеш-таблицы (отношение количества элементов к размеру таблицы) критически важна для ее производительности. При слишком высокой загрузке увеличивается вероятность коллизий, что может привести к ухудшению времени поиска. Обычно рекомендуется поддерживать загрузку на уровне 0.7–0.8, чтобы обеспечить баланс между использованием памяти и эффективностью операций.

Содержание
Концепция хеширования распределяет записи (пары ключ/значение) по массиву, называемому ведром. Алгоритм вычисляет индекс на основе заданного ключа, указывая, где находится соответствующая запись.
В этом методе хэш не зависит от размера массива. Индекс вычисляется с помощью операции по модулю ( % ), что дает число в диапазоне от 0 до размера массива минус один.
Если размер массива — степень двойки, остаток можно получить с помощью маскирования, что ускоряет работу. Однако это может вызвать проблемы при использовании неэффективной хэш-функции.
Выбор хеш-функции

Идеальная хеш-функция
Если ключи известны заранее, можно использовать идеальную хеш-функцию для создания хеш-таблицы без коллизий. При минимальном идеальном хешировании любое место в таблице может быть использовано.
- Главное преимущество хеш-таблиц — скорость. Это особенно заметно при работе с большим объемом записей. Хеш-таблицы эффективны, если заранее известно максимальное количество записей, что позволяет выделить массив сегментов оптимального размера и избежать его изменения.
- Если набор пар ключ-значение фиксирован и известен заранее, можно значительно снизить среднюю стоимость поиска, тщательно подбирая хеш-функцию, размер корзины и внутренние структуры данных. Можно создать хеш-функцию без конфликтов или даже идеальную, что позволит не хранить ключи в таблице.
Распространенные алгоритмы и структуры данных в JavaScript: объекты и хеширование
Когда коэффициент загрузки приближается к 0, доля неиспользуемых областей в хеш-таблице увеличивается, но не обязательно какое-либо снижение стоимости поиска.
 Читайте также:
Читайте также:
Ключевая статистика
Низкий коэффициент загрузки не приносит выгоды. При его снижении до 0 количество неиспользуемых ячеек в хеш-таблице увеличивается, но это не всегда сокращает время поиска. В итоге происходит неэффективное использование памяти.
Отдельная цепочка
В методе, известном как отдельная цепочка , каждая корзина независима и имеет своего рода список записей с одинаковым индексом. Время для операций с хеш-таблицей — это время на поиск сегмента (которое является постоянным) плюс время для операции со списком.
Есть несколько реализаций, которые обеспечивают отличную производительность как для времени, так и для пространства, при этом среднее количество элементов в ведре находится в диапазоне от 5 до 100.
Отдельная цепочка со связанными списками
Связанные хэш-таблицы, основанные на связанных списках, популярны благодаря своей зависимости от базовых структур данных и простых алгоритмов. Они могут использовать элементарные хеш-функции, которые не всегда подходят для других методов.
Отдельная цепочка с ячейками заголовка списка
Некоторые реализации цепочки хранят первую запись каждой цепочки в самом массиве слотов. Количество обходов указателя в большинстве случаев уменьшается на единицу. Цель состоит в том, чтобы повысить эффективность кеширования доступа к хеш-таблице.
Недостатком является то, что пустое ведро занимает то же место, что и ведро с одной записью. Для экономии места в таких хэш-таблицах часто бывает столько же слотов, сколько хранимых записей, а это означает, что многие слоты имеют две или более записей.
Отдельная цепочка с другими структурами
Открытая адресация
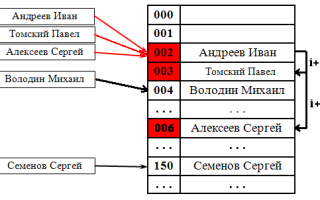
Коллизия хэшей разрешена путем открытой адресации с линейным зондированием (интервал = 1). Обратите внимание, что «Тед Бейкер» имеет уникальный хеш, но, тем не менее, столкнулся с «Сандрой Ди», которая ранее столкнулась с «Джоном Смитом».
- Линейное зондирование , при котором интервал между зондами фиксирован (обычно 1). Благодаря хорошему использованию кэша ЦП и высокой производительности этот алгоритм наиболее широко используется на современных компьютерных архитектурах в реализациях хэш-таблиц.
- Квадратичное зондирование , при котором интервал между зондами увеличивается путем добавления последовательных выходов квадратичного полинома к начальному значению, заданному исходным вычислением хеш-функции.
- Двойное хеширование , при котором интервал между зондами вычисляется второй хеш-функцией.
Объединенное хеширование
Кукушка хеширования
Классическое хеширование
Робин Гуд хеширование
Хеширование с двумя вариантами
Основное достоинство хэш-таблиц — высокая скорость работы, особенно при большом объеме записей. Эффективность хэш-таблиц проявляется, когда известно максимальное количество записей, что позволяет выделить массив сегментов с оптимальными размерами и избежать изменений в будущем.
Если набор пар ключ-значение фиксирован, можно значительно снизить среднюю стоимость поиска, тщательно подбирая хэш-функцию, размер корзины и внутренние структуры данных. Возможно создать хэш-функцию, которая полностью исключает конфликты или достигает идеального результата, что позволяет не хранить ключи в таблице.
Основные принципы разработки алгоритмов — Студопедия
Отсюда понятно, что если d Theta n 2 , то ожидание равно константе, а если d асимптотически больше или меньше, то X стремится нулю или бесконечности соответственно.
Динамическое изменение размера
Изменение размера путем копирования всех записей
Альтернативы перефразированию «все и сразу»
Дисковые хеш-таблицы обычно используют альтернативные методы вместо полного повторного хеширования, поскольку восстановление всей таблицы на диске может быть слишком затратным.
Постепенное изменение размера
Чтобы обеспечить полное копирование старой таблицы до того, как потребуется увеличить новую таблицу, необходимо увеличить размер таблицы как минимум в (р + 1)/р во время изменения размера.
Монотонные клавиши
Общее число записей обычно удваивается, поэтому количество подинтервалов для проверки составит O(N). Время для двоичного поиска перенаправления составит O(log(log(N))).
Линейное хеширование
Линейное хеширование [28] представляет собой алгоритм хеш-таблицы, который разрешает инкрементное расширение хеш-таблицы. Он реализован с использованием одной хэш-таблицы, но с двумя возможными функциями поиска.
Хеширование для распределенных хеш-таблиц
Хеширование с двумя вариантами [ править ]
Чтобы обеспечить полное копирование старой таблицы до того, как потребуется увеличить новую таблицу, необходимо увеличить размер таблицы по крайней мере в r 1 r во время изменения размера.
Вероятность ошибки и почему это всё вообще работает
Практическое правило: для сохранения (n) уникальных хэшей оптимально использовать модуль порядка (10 cdot n^2). Это основано на парадоксе дней рождений.
Если выбрать один слишком большой модуль, может произойти переполнение. В таких случаях целесообразно использовать два или три модуля для параллельной обработки множества хэшей.
СОДЕРЖАНИЕ
Помимо восстановления записи с заданным ключом, многие реализации хеш-таблиц также могут определить, существует ли такая запись или нет.
Использование хеш-таблиц
Объекты и хеш-таблицы часто используются для оптимизации процессов, например, для подсчета появления символов в строке.
Хеширование — это алгоритм, работающий в одном направлении. Из хеша невозможно восстановить исходное значение, что не является необходимым, так как цель хеширования — различать входные данные.
В некоторых случаях требуется двустороннее преобразование, например, для отправки секретного сообщения другу, которое никто другой не сможет прочитать. В таких ситуациях применяются алгоритмы шифрования.
Тестирование и оценка производительности хеш-функции
Тестирование и оценка производительности хеш-функции являются критически важными этапами при разработке хеш-таблиц с открытой адресацией. Эффективность хеш-функции напрямую влияет на скорость операций вставки, поиска и удаления элементов, а также на общее использование памяти. В этом разделе мы рассмотрим основные методы тестирования хеш-функций и критерии, по которым можно оценить их производительность.
Первым шагом в тестировании хеш-функции является анализ ее распределения. Хорошая хеш-функция должна равномерно распределять ключи по всей области хеш-таблицы, минимизируя количество коллизий. Для этого можно использовать статистические методы, такие как тесты на равномерность распределения, например, тест χ² (хи-квадрат). Этот тест позволяет определить, насколько равномерно распределены хеш-значения по всем возможным индексам таблицы.
Следующим важным аспектом является измерение времени выполнения операций. Для этого можно использовать таймеры, чтобы зафиксировать время, необходимое для выполнения операций вставки, поиска и удаления элементов в хеш-таблице. Эти замеры следует проводить при различных нагрузках, чтобы понять, как производительность хеш-функции изменяется в зависимости от количества элементов в таблице. Также стоит учитывать, что производительность может варьироваться в зависимости от типа данных, которые используются в качестве ключей.
Еще одним критерием оценки производительности хеш-функции является количество коллизий. Коллизия происходит, когда два разных ключа хешируются в один и тот же индекс. Высокое количество коллизий может значительно замедлить операции, так как потребуется дополнительное время для разрешения конфликтов. Для оценки этого показателя можно использовать коэффициент загрузки (load factor), который определяется как отношение количества элементов в таблице к размеру таблицы. Чем выше коэффициент загрузки, тем больше вероятность коллизий.
Кроме того, важно учитывать, как хеш-функция справляется с различными типами входных данных. Например, если хеш-функция используется для строк, необходимо протестировать ее на различных наборах строк, включая короткие и длинные, случайные и предсказуемые. Это поможет выявить слабые места хеш-функции и улучшить ее производительность.
Наконец, стоит отметить, что хеш-функции могут быть оценены не только по их производительности, но и по другим критериям, таким как простота реализации и устойчивость к атакам. Например, в некоторых случаях может быть важно, чтобы хеш-функция была стойкой к предсказанию, чтобы предотвратить атаки, основанные на анализе хеш-значений.
В заключение, тестирование и оценка производительности хеш-функции являются важными аспектами разработки хеш-таблиц с открытой адресацией. Используя различные методы анализа, можно выбрать наиболее подходящую хеш-функцию, которая обеспечит высокую производительность и надежность при работе с данными.
Вопрос-ответ
Как работает открытая адресация в хеш-таблицах?
Открытая адресация. Алгоритм вставки элемента проверяет ячейки массива H в некотором порядке до тех пор, пока не будет найдена первая свободная ячейка, в которую и будет записан новый элемент. Этот порядок вычисляется на лету, что позволяет сэкономить на памяти для указателей, требующихся в хеш-таблицах с цепочками.
Что такое хэш-функция Hashtable?
Хеш-таблица использует хеш-функцию для вычисления индекса, также называемого хеш-кодом, в массиве сегментов или слотов, из которого можно найти нужное значение. Во время поиска ключ хешируется, и полученный хеш указывает, где хранится соответствующее значение.
Что такое Хэш-функция и зачем нужны хэш таблицы в C#?
Хэш-функция — это алгоритм, который возвращает числовый хэш-код на основе ключа. Ключ — это значение некоторого свойства хранимого объекта. Хэш-функция всегда должна возвращать один хэш-код для одного и того же ключа.
Что такое коллизия хеш-таблиц?
Коллизии в хеш-таблицах возникают, когда два или более ключа имеют одинаковый хеш-код и, следовательно, претендуют на одну и ту же позицию в таблице. Для решения этой проблемы существуют различные методы, каждый из которых имеет свои преимущества и недостатки в зависимости от контекста применения.
Советы
СОВЕТ №1
Выбирайте хеш-функцию, которая равномерно распределяет ключи по всей таблице. Это поможет минимизировать количество коллизий и улучшит производительность вашей хеш-таблицы. Попробуйте использовать простые хеш-функции, такие как умножение или сложение, и протестируйте их на ваших данных.
СОВЕТ №2
Обратите внимание на размер хеш-таблицы. Он должен быть достаточным для хранения всех элементов, но не слишком большим, чтобы не тратить память. Рекомендуется использовать простые числа в качестве размера таблицы, так как это может улучшить распределение ключей.
СОВЕТ №3
При реализации открытой адресации используйте метод линейного или квадратичного пробирования для разрешения коллизий. Это поможет вам эффективно находить свободные ячейки в случае, если выбранный индекс уже занят.
СОВЕТ №4
Не забывайте о необходимости динамического изменения размера хеш-таблицы. Если количество элементов превышает определенный порог, увеличьте размер таблицы и перераспределите существующие ключи, чтобы сохранить производительность.